

過去記事ではスキャンデータからjpgファイルのフォルダを作成した後にChainLPで読み込んで電子書籍データを作っていました。
その場合だとスキャンしたPDFデータをAcrobat Pro等で処理しないといけないのですが、今回はChainLPのみでPDFスキャンデータを入力し、電子書籍データを出力してみます。
このページの事例ではNew Kindle Paperwhite(2015ニューモデル)に最適化したデータを出力します。
PDFを処理する場合は「圧縮ファイルを読み込む」
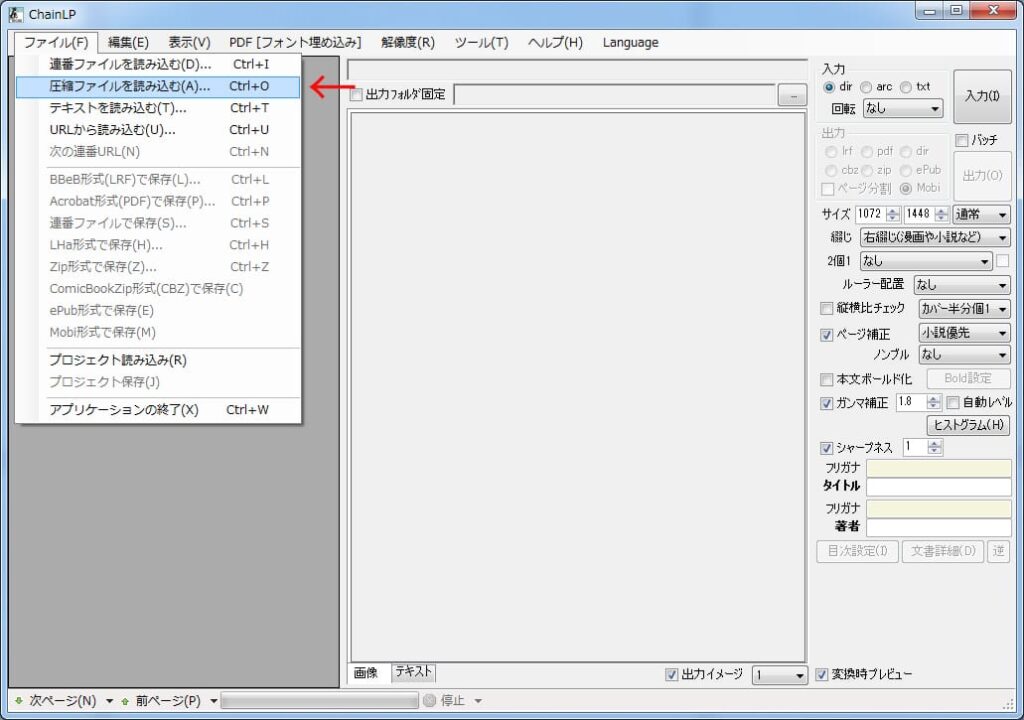
jpgデータの入ったフォルダを処理する場合は「連番ファイルを読み込む」でしたが、PDFデータの場合は「圧縮ファイルを読み込む」でデータを読み込みます。
PDFの上下左右のスキャン余白をトリミングします。
「編集(E)」→「トリミング&余白 Ctrl+Shift+T」
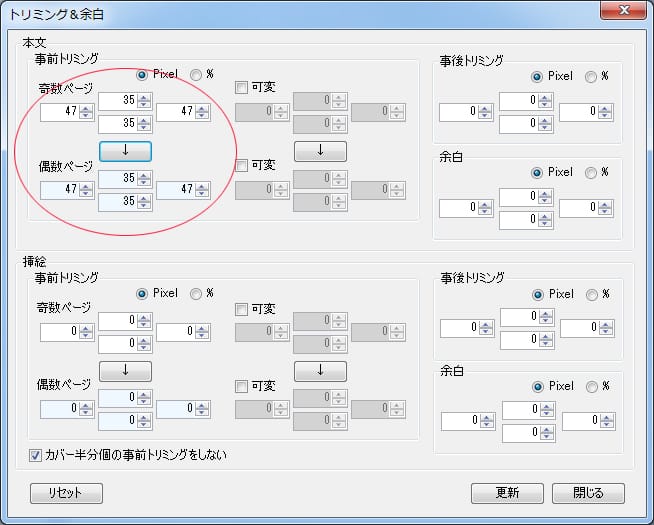
スキャンしたデータは上下左右に原稿の影が付いたりしますので、事前トリミングの指定をします。
私の場合は偶数ページも奇数ページも同じように、左右2ミリ・上下1.5ミリを除去しています。
Pixel指定なので、トリミングする値は「上下:35Pixel、左右:47Pixel」になります(New Kindle Paperwhiteの場合)。
真ん中の下向き矢印を押すと奇数ページの入力データが偶数ページにコピーされます。
スキャンデータによっては奇数ページと偶数ページの余白が異なる場合がありますので、設定値を変えることも出来ます。
更新ボタンを押せば「絵」チェックボックスにチェックが入っていない全てのページが処理されます。
「絵」のページは「挿絵」の事前トリミングを設定します。
事前トリミング設定前の状態
読み込んだ画像の上下左右に影のようなぼけが入っているのが分かります。
事前トリミング設定後の状態
読み込んだ画像の上下左右がきれいに切り取られています。
後はChainLPの出力ボタンを押せばできあがりです。
このようにChainLPさえあれば、電子書籍端末に最適化したデータを作ることが出来ます。
私はChainLP開発者のNo.722さんを心からリスペクトしています。
電子化ノウハウのまとめページを作りました。

www.bluelady.jp
by Amazon


コメント